Stage 1: Identify Scenario Components
Identify the Asset at Risk
The first thing we need to figure out is: “What are we trying to protect?” Another way to put it is to find out where something valuable or risky exists. For example, do we consider the login details as the thing we need to protect, or is it the programs, devices, and data that those login details give access to? The simple answer is “they’re all important.” But for now, let’s concentrate on the login details, knowing that their importance comes from the things they’re meant to keep safe.
Identify the Threat Community
The next thing we need to figure out is: “What risks are we dealing with?” Think of it this way: Imagine you’re running a company, and you’re trying to understand what could potentially harm your business. To do that, you need to look at what kind of business you’re in and the situation surrounding your assets. For instance, if you’re thinking about the risk to something like an HR manager’s office, you need to consider who might pose a threat.
We can divide these potential threats into different groups based on who they are and how likely they are to cause harm. But we don’t want to go overboard and analyze every single possible threat out there—that would take forever! For example, in this case, it’s probably not necessary to worry about something as extreme as a spy from a foreign intelligence agency targeting the company.
Instead, let’s focus on the more likely scenarios. In this case, it makes sense to think about risks from:
– The cleaning staff
– Other HR employees who regularly go into the executive’s office
– Visitors to the office
– Guests
– People applying for jobs
– Technical support staff
As we gain more experience, we get better at figuring out which groups we should be concerned about and which ones we can ignore. We might even decide to group some of these together, like combining all types of visitors.
In this example, let’s pay special attention to the risk from the cleaning crew. They’re a group that often gets overlooked, but they have regular access to sensitive areas like the executive’s office.
Stage 2: Evaluate Loss Event Frequency (LEF)
Estimate the Probable Threat Event Frequency (TEF)
Many people want solid evidence before they feel comfortable estimating how often attacks might happen. But in many cases, there’s not much useful or trustworthy data available. So, we often end up ignoring this aspect altogether. But when we do that, we’re not really talking about risk anymore.
So, what do we do when we don’t have hard numbers to work with? One option is to use words like “Low,” “Medium,” or “High” to describe the level of risk. While this qualitative approach can be okay in some situations, using numbers gives a clearer picture and is more helpful for decision-makers, even if it’s not exact.
For instance, let’s say we don’t have data on how often cleaning staff might misuse usernames and passwords left lying around. But we can make a reasonable guess within certain ranges.
This guess would consider how often the cleaning staff come into contact with these credentials and how likely they are to misuse them. Factors like how valuable the information is to them, how easy it seems to misuse, and the risk of getting caught all play a role.
Given that cleaning staff are usually honest, that the credentials might not seem valuable to them, and that the risk of getting caught might be high, we might estimate a low risk using a scale like this:
– Very High: More than 100 times a year
– High: Between 10 and 100 times a year
– Moderate: Between 1 and 10 times a year
– Low: Between 0.1 and 1 times a year
– Very Low: Less than 0.1 times a year (less than once every 10 years)
Could there be a cleaning staff member with a motive, enough knowledge to understand the value of the credentials, and a willingness to take the risk? Absolutely! Does it happen? Probably. Could it be someone in the cleaning crew here? It’s possible. But overall, it’s likely a rare occurrence.
Estimate the Threat Capability (TCap)
Threat Capability (Tcap) is essentially about assessing how skilled and resourced a potential threat is in targeting something valuable, like your data or passwords. Let’s break it down in simpler terms.
Imagine you have a password written on a sticky note. Now, think about who might try to get that password. The cleaning crew, for instance, might have a medium level of ability to do so. We’re talking about how good they are at reading (skill) and how much time they have (resources) to do it.
Now, we have a scale to rate these capabilities:
– Very High (VH): Think of this as the top 2% of threat actors out there.
– High (H): This is like the top 16%.
– Moderate (M): This is just average, falling somewhere between the least skilled and the most skilled.
– Low (L): This is like the least skilled, bottom 16%.
– Very Low (VL): And this is the bottom 2%.
It’s important to remember that these ratings are always relative to the situation. So, if we were worried about a different kind of attack, like hacking a website, the cleaning crew might not be as much of a concern.
Estimate Control Strength (CS)
Control Strength (CS) refers to how well a security measure can prevent unauthorized access to something valuable, like data or resources. In our case, if sensitive information like login details is easily visible and not protected, the Control Strength is deemed Very Low. However, if the information is written down but encrypted, the Control Strength would likely be much higher.
Here’s what the ratings mean:
– Very High (VH): Provides strong protection against almost all but the most sophisticated threats.
– High (H): Offers good protection against the majority of threats.
– Moderate (M): Provides average protection against common threats.
– Low (L): Only offers limited protection against less skilled attackers.
– Very Low (VL): Provides minimal protection, mainly against the least skilled attackers.
You might wonder, “Aren’t good hiring practices or locks on doors controls for internal assets?” Yes, they are. However, these controls affect how often a potential threat can interact with the asset rather than directly determining how effective the control is when an attack occurs.
Derive Vulnerability (Vuln)
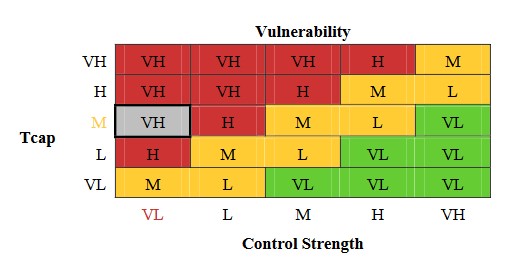
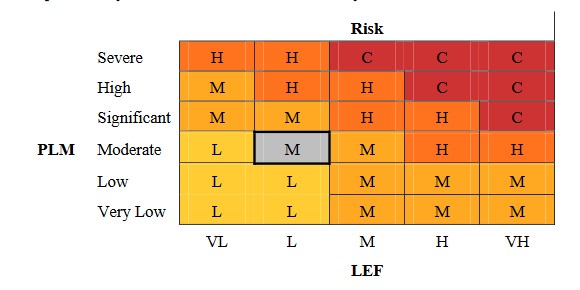
Finding vulnerability is straightforward once you’ve identified your Threat Capability (Tcap) and Asset Criticality Score (CS). Remember from Section 5.2.6 that vulnerability refers to how susceptible an asset is to a potential threat. It’s essentially the difference between the force of a potential attack and the asset’s ability to withstand that attack. To determine vulnerability, you can use the matrix provided below. Just locate the Tcap on the left side of the matrix and the CS along the bottom. Where they meet in the matrix gives you the vulnerability level.
Derive Loss Event Frequency (LEF)
Similar to vulnerability, LEF is derived by intersecting TEF and Vulnerability within a matrix.
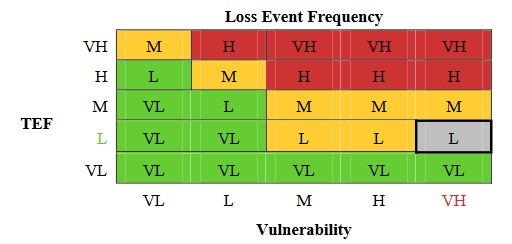
In our situation, if we have a low level of tolerance for error (TEF) and a very high vulnerability, our level of exposure to risk (LEF) will also be low. It’s important to understand that vulnerability is measured as a percentage, meaning it can’t exceed 100%. So, our exposure to risk will never be higher than our tolerance for error.
Stage 3: Evaluate Probable Loss Magnitude (PLM)
Based on the previous steps, we’ve figured out that the chances of something going wrong in our situation are pretty low (probably happening between 0.1 to 1 time per year). Now, we need to think about what would happen if something bad actually does occur.
Remember how we talked about usernames and passwords earlier? Well, they basically carry the same importance and risk as the stuff they let you access. So, if you’re an HR executive, those credentials likely give you access to a bunch of HR-related stuff like organizational charts, employee info (like performance, health, address, salary, etc.). Depending on where you are in the company, you might also get your hands on some company strategy stuff. But for now, let’s say our HR exec doesn’t have access to super-secret corporate strategies.
Estimate Worst-Case Loss
In this situation, there are three main ways that could cause us significant problems:
– Misuse: This is when someone uses the information in employee records to pretend to be someone else, like stealing their identity. This could lead to legal trouble and damage our reputation.
– Disclosure: Employee records often have private information, like medical or performance details. If this information gets out, it could cause legal issues and harm our reputation.
– Denying access or destroying records: Employee records are really important for running a business smoothly. If they’re destroyed, it could make it harder for us to get things done, leading to lost productivity.
Sometimes we need to figure out which of these threats is the most serious. For now, let’s say disclosure is the worst-case scenario.
Our next step is to figure out how bad things could get if any of these threats actually happen.
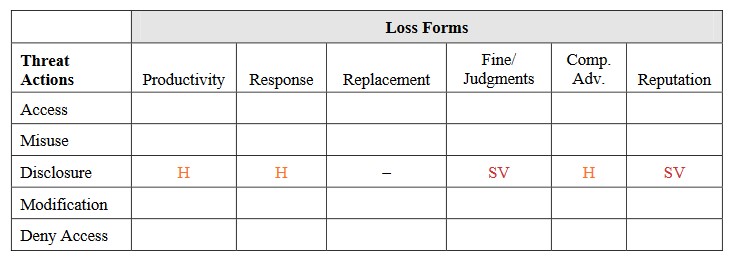
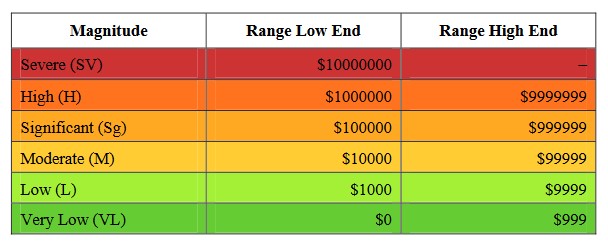
Keep in mind that we didn’t calculate how bad things could get if we had to replace anything. When we’re looking at how bad a situation could be, if one of the ways things could go wrong would be really, really bad, we usually don’t worry too much about the other ways that aren’t as bad.
So, in this case, replacing stuff isn’t something we’re worried about because nothing’s actually getting destroyed. Here’s why we think things could get really bad:
– People might not work as well because they’re distracted.
– We might have to spend a lot of money on lawyers, especially if people start suing us.
– If sensitive information gets out, we could end up paying a lot in legal fees or fines, especially if it affects a lot of people.
– If our competitors find out about any mistakes we’ve made, they might use that against us. But usually, they’ll just wait for our customers to get upset and come to them instead.
– If the public finds out about what happened and it’s really bad, our reputation could take a big hit. This could make customers leave and our stock value drop.
Remember, these are just guesses based on what could happen. We don’t always write down all the reasons behind our guesses, but knowing more about why things might go wrong helps us make better guesses.
Also, when we think about the worst-case scenario, we’re not really thinking about how likely it is to happen. In this case, we’ve decided that the worst thing that could happen would cost us a lot of money, but it’s not very likely.
There are lots of things that could make the worst-case scenario more or less likely. For example, someone could accidentally leak information, or someone could steal it and get caught. But even if the worst thing does happen, we can still try to make it better by how we respond. So, it’s not always worth spending a ton of time trying to figure out exactly how likely the worst-case scenario is. Just understand the main factors and roughly where the worst-case scenario falls on a scale from “probably going to happen” to “probably won’t happen.”
In our case, we’re saying the worst-case scenario would cost us a lot of money, but it’s not very likely to happen.
Estimate Probable Loss Magnitude (PLM)
To figure out how much potential harm there might be in a certain situation, like someone trying to steal personal information, we need to first figure out what the most likely threat is. Usually, people do things because they want something out of it, and when it comes to illegal activities, money is often the main motivation. So, considering the kinds of threats out there and what they could do with personal info, it’s sensible to think that someone might try to misuse it, like for identity theft.
Once we’ve identified that, our next job is to figure out how much damage could be done if someone does misuse that information in different ways.
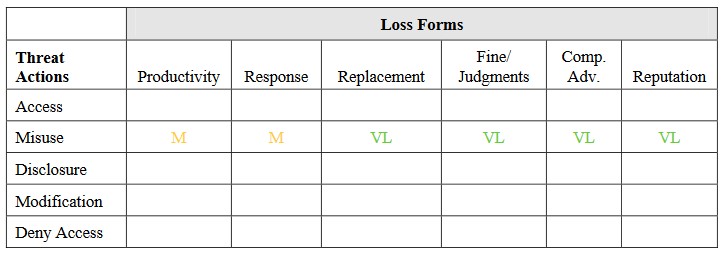
Our estimates are based on a few factors:
- Employees might be a bit less productive for a while because of what happened.
- We’ll have to spend some money on looking into what happened, getting advice from our legal team, and maybe compensating affected employees.
- Changing the executive’s password won’t cost much.
- We won’t face any legal trouble or fines because we’re handling the situation internally.
- We won’t lose any advantage over competitors because what happened isn’t a big deal.
- Our reputation won’t take a hit because it was an internal issue, no customers were affected, and we have good security measures in place.
We made these estimates based on a few assumptions:
- We found out about what happened. Sometimes these things can go unnoticed, but until we know about them, they don’t really hurt us.
- Only a small number of employees might have had their identities stolen.
- We responded well to the situation.
Stage 4: Derive and Articulate Risk
We’ve tackled the challenging part already – figuring out the risk. It boils down to two things: how likely a bad event is to happen (LEF) and how much damage it could do (PLM). Now, we’re deciding how to talk about this risk. We can describe it in a few ways: using a fancy chart, or just by talking about LEF, PLM, and the worst-case scenario.
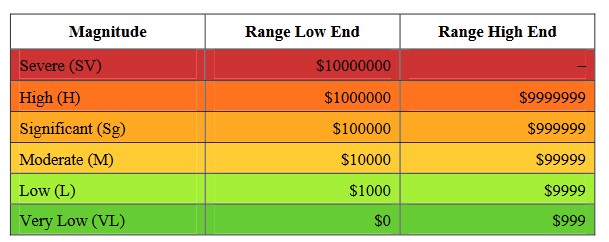
In this exercise, we’ll try both approaches. Let’s say our pretend bank’s big bosses have given the thumbs up to the chart below. According to that chart, the risk from this group of threats is medium. That’s because the chance of bad stuff happening (LEF) is pretty low (somewhere between 0.1 and 1 times a year), and the potential damage (PLM) is moderate (between $10K and $100K).
We can also tell the decision-makers that while the worst-case scenario could be really bad, it’s not likely to happen.
When we talk about analyzing risks, there are several important things to consider. Imagine organizing these considerations into four main categories:
1. Complexity of the Model: The model we use to understand risks can sometimes be very detailed, which might seem overwhelming at first. However, this detail allows us to dive deep into understanding different aspects of risk. Thankfully, we don’t always need to explore every intricate detail. We can adjust the level of analysis based on what information we have and how much time we have available. Having a detailed model has its advantages too – it helps us better understand what contributes to a risk and allows us to spot potential issues more easily.
2. Availability of Data: Good data is crucial for understanding and estimating risks accurately. But sometimes, especially for rare events, finding good data can be challenging. Even though we might not have all the data we want, having a framework like FAIR helps us organize the data we do have and make informed estimates. And when data is scarce, we can use what we do know to guide our estimates, adjusting them as we gather more information over time.
3. Iterative Risk Analyses: Analyzing risk is rarely a one-time thing. It’s more like a journey where we start with some initial assessments and then refine our understanding as we go along. Each analysis builds on the last, helping us get closer to a more accurate picture of the risks we face. However, there’s a balance to strike – going too deep into analysis can become impractical in terms of time and resources.
4. Perspective: Some people prefer to focus on “exposure” rather than “risk.” They see risk as the worst-case scenario before any safeguards are put in place, while exposure represents the risk that remains after protections are applied. Both perspectives are important and can be analyzed using the FAIR framework, which allows us to look at risks both with and without mitigation measures.
In essence, while understanding and communicating about risks can be complex, having a structured framework like FAIR helps us make sense of it all. It’s not about making things overly complicated; it’s about using the right tools to understand and manage risks effectively.